
Gdy dopiero zaczynasz przygodę z programowaniem trudno jest wiedzieć wszystko od samego początku. To całkiem normalne, że rozwijasz swoje programistyczne umiejętności krok po kroku. Dziś chcę Ci pomóc w lepszym zrozumieniu komendy git rebase. Jest to bardzo pożyteczne polecenie, gdy chcesz mieć w przejrzysty sposób uporządkowane zmiany w repozytorium.
Ten artykuł jest trzecim artykułem z serii o narzędziu git. Jeżeli chcesz dowiedzieć się więcej o podstawowym użyciu git-a to zapraszam do mojego poprzedniego artykułu w tym cyklu.
Git merge
Prawdopodobnie, gdy zaczęłaś pracować z gałęziami (ang. branch), do ich łączenia używałaś polecenia git merge. To polecenie sprawia, że zmiany jakie masz na swojej gałęzi, możesz połączyć na przykład z gałęzią główną. To jest ok. Robi dokładnie to, co chcesz uzyskać. Jednak gdy przyjrzysz się bliżej w jaki sposób Twoje zmiany zostały połączone z główna gałęzią (ang. master branch) zauważysz, że wyświetlają się one w jakiś taki nielogiczny sposób. Zmiany w repozytorium są pogrupowane względem czasu utworzenia, a nie względem funkcjonalności. Można się w tym pogubić.
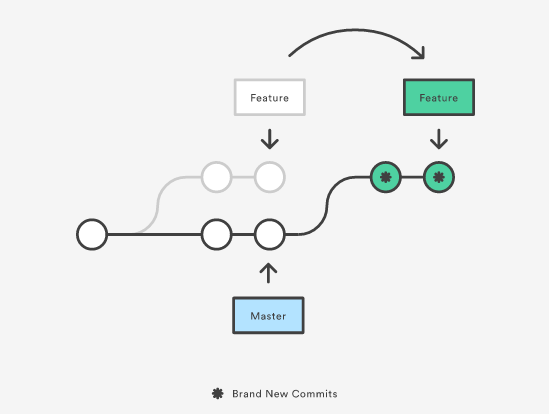
Wyobraź sobie, że masz do wprowadzenia funkcjonalność logowania w swojej aplikacji. Pierwsza Twoja zmiana (commit) dotyczy czystego HTML-a, tego jak ma to wyglądać w przeglądarce. W drugim kroku zajmujesz się zaimplementowaniem logiki po stronie serwera. Te dwie zmiany tworzą logiczną całość. Dotyczą jednej funkcjonalności. Decydujesz się na dołączenie swoich zmian do gałęzi głównej. Tymczasem Twój zespół pracował też nad innymi zmianami i teraz po połączeniu wszystkiego razem jedna z Twoich zmian jest na samej górze git-owego drzewa, a druga gdzieś po środku. Trudno tu zauważyć jakiś związek między tymi zmianami. Niełatwo jest również odtworzyć sposób myślenia programisty/programistki. Całość mogłaby wyglądać podobnie jak na obrazku.

Widać, że zmiany, które tworzą logiczną całość po dołączeniu do gałęzi develop zostają przeplecione innymi zmianami. Wszystko powoduje wrażenie bałaganu i nieładu. Dodatkowo pojawiły się zmiany, których sama nie stworzyłaś. Te z tytułem merge. Powstają one w momencie łączenia zmian i widać w nich pliki, które były modyfikowane przez więcej niż jedną osobę
Git rebase
Przejdźmy do git rebase. Jeżeli zależy Ci na zachowaniu tej logicznej kolejności Twoich zmian, to naprawdę warto korzystać z git rebase. To rozwiązanie grupuje zmiany według kolejności ich wprowadzania w obrębie jednej gałęzi, a nie według tego kiedy zostały utworzone. By widzieć efekty działania git rebase cały Twój zespół powinien z niego korzystać.

Tutaj wszystko ma swoje miejsce. Zmiany są pogrupowane w logiczne całości. Dodatkowo widać historię naszych gałęzi.
Pora zająć się dokładniejszym zrozumieniem tego, co dzieje się podczas git merge i git rebase.
Git merge vs git rebase
Jeżeli używasz komendy git merge, to git stara się rozwiązać wszystkie konflikty naraz. Umieszcza zmiany w kolejności czasu utworzenia, co powoduje, że Twoje zmiany lądują między zmianami innych członków zespołu. Po rozwiązaniu wszystkich powstałych konfliktów tworzony jest dodatkowy merge commit, gdzie znajdują się informacje o tym jak konflikty zostały rozwiązane. W przypadku użycia komendy rebase, git przenosi wszystkie Twoje zmiany z bieżącej gałęzi do tymczasowej lokalizacji. Następnie dociąga wszystkie zmiany z gałęzi, z którą chcesz się połączyć. Na koniec pojedynczo umieszcza Twoje zmiany powyżej dołączonych wcześniej zmian. Mówimy wtedy, jesteśmy na samej górze HEAD (ang. on top of the HEAD).
Co to jest HEAD?
HEAD to referencja do ostatniej zmiany na Twojej bieżącej gałęzi. Można powiedzieć, że HEAD jest czymś w rodzaju takiego znacznika, który mówi Ci gdzie teraz jesteś. Kiedy na Twoim zdalnym repozytorium są zmiany, których jeszcze nie masz u siebie lokalnie, możesz powiedzieć, że jesteś za zdalnym HEAD (czyli za tym bieżącym znacznikiem na zdalnym repozytorium). Po angielsku powiedziałabyś behind the remote HEAD. Kiedy już dociągniesz brakujące zmiany do swojego lokalnego repozytorium, to możesz powiedzieć, że jesteś na bieżąco ze zdalnym HEAD (ang. on top of the HEAD). Jest też możliwe przesunięcie HEAD na konkretną zmianę. Wtedy mówimy, że HEAD jest odłączony (ang. detached). Znaczy to tyle, że HEAD zamiast wskazywać na ostatnie zmiany konkretnej gałęzi, wskazuje na jakąś wybraną zmianę - commit. Co jest zilustrowane poniżej:
HEAD (refers to commit 'B')
|
v
A---B---C---D branch 'master' (refers to commit 'D')
Jak używać git rebase?
Najprostszy scenariusz - brak konfliktów
Poniżej możesz zobaczyć jak wykorzystać git rebase w przypadku, gdy chcesz użyć go do aktualizacji gałęzi my-branch na podstawie gałęzi develop.
Przejdź na gałąź
developgit checkout developDociągnij lokalnie najnowsze zmiany
git pull developPrzełącz się na wybraną gałąź
git checkout my-branchUżyj polecenia
git rebasegit rebase developWyślij zmiany na zdalne repozytorium
git push
Git rebase i rozwiązywanie konfliktów
Powyżej mogłaś zobaczyć jak wygląda najprostszy scenariusz użycia git rebase. Nie zawsze jednak jest tak łatwo. Czasami, gdy będziesz używać git rebase, możesz mieć do rozwiązania konflikty. Musisz je rozwiązać zanim przejdziesz do kolejnego kroku polecania rebase. Najpierw znajdujesz wszystkie pliki z konfliktami. Będziesz ich listę widzieć wypisaną w terminalu. Rozwiązujesz zaznaczone konflikty. Dodajesz swoje zmiany za pomocą komendy git add, by były dalej śledzone. Na koniec dajesz do zrozumienia git-owi, że może kontynuować swoją pracę. Używasz do tego polecenia git rebase --continue.
git rebase develop
# rozwiązanie konfliktów
git add -u # dodanie wszystkich zmian do śledzenia
git rebase --continue
Brak zmian do zatwierdzenia po rozwiązaniu konfliktów
Może się też zdarzyć, że po rozwiązaniu wszystkich konfliktów dostaniesz informacje, że git nie widzi, w porównaniu do poprzedniego kroku, żadnych nowych zmian. By móc przejść do następnego etapu trzeba ręcznie poinformować git-a, że zdajesz sobie z tego sprawę i chcesz kontynuować. Oczywiście jeżeli to nie jest pomyłka z Twojej strony. By to zrobić użyj polecenia:
git rebase --skip
Nie mogę zrobić push na zdalne repozytorium po git rebase
Prawdopodobnie miałaś już zmiany na zdalnym repozytorium zanim zaczęłaś robić git rebase. Nie martw się. To dość częsty przypadek. Istnieje na niego proste rozwiązanie. Zanim jednak Ci je pokażę, chciałabym abyś zrozumiała dlaczego tak się dzieje. Dlaczego nie możesz wysłać zmian na zdalne repozytorium po wykonaniu polecania git rebase? Kiedy używasz git rebase, jak to już wspominałam wcześniej, git przenosi wszystkie Twoje zmiany z bieżącej gałęzi do tymczasowej lokalizacji. Po dołączeniu brakujących zmian z gałęzi z którą chcesz się zsynchronizować, pojedynczo umieszcza Twoje zmiany z powrotem na bieżącej gałęzi. Twój kod pozostaje taki sam, jednak każda zmiana dostaje nowy identyfikator. Te identyfikatory, które zmiany posiadały przed rebase przestają istnieć. No i tu pojawia się problem. Na zdalnym repozytorium dalej masz stare identyfikatory. Pomagały one w określaniu, co już znalazło się na zdalnym repozytorium a co nie. Teraz git nie wie co zrobić, bo ma jakby kompletnie nowe zmiany całkowicie nie powiązane z tym, co jest na zdalnym repozytorium. Dzieje się tak, ponieważ polecenie git rebase nadpisuje całą historię zmian danej gałęzi. W końcu dorzuciłaś tam kilka zmian z innej gałęzi. By rozwiązać ten problem trzeba wymusić nadpisanie historii zmian również na zdalnym repozytorium.
git push -f origin my-branch
# albo bardziej opisowo
git push --force origin my-branch
Musisz jednak uważać. Jeżeli podczas git rebase coś poszło nie tak, przykładowo przy rozwiązywaniu konfliktów, możesz stracić swoje zmiany. Jeżeli na gałęzi pracujesz samodzielnie jest to mało prawdopodobne, że źle rozwiązałaś konflikty. W przypadku pracy na jednej gałęzi z innymi, czego nie polecam, może być różnie.
Jak zrezygnować z rozpoczętego git rebase?
W każdej chwili w trakcie robienia git rebase możesz zrezygnować z jego kontynuacji. Do tego celu służy polecenie:
git rebase --abort
Inne artykuły w cyklu:
- Co to jest git?
- Podstawowe komendy narzędzia Git
- Jak zmienić gałąź rodzicielską w git-cie?
- Jak użyć komendy git rebase –onto?
Jeżeli interesuje Cię więcej informacji na temat narzędzia git, możesz zajrzeć na stronę dokumentacji git-a.